MySQL 学习总结
志正则众邪不生,心静则众事不躁。
导航
1、语句总览
SQL 语句分为两个大类:数据操作语言(DML)和数据定义语言(DDL)。
(1)数据操作语言(DML)主要是针对表的操作:
-
INSERT INTO - 向数据库表中插入数据(增)
-
DELETE FROM - 从数据库表中删除数据(删)
-
SELECT ... FROM - 从数据库表中获取数据(查)
-
UPDATE ... SET - 更新数据库表中的数据(改)
(2)数据定义语言 (DDL) 主要是针对库及表自身的操作:
- CREATE DATABASE - 创建数据库(增)
- DROP DATABASE - 删除数据库(删)
- SHOW DATABASES - 列出数据库(查)
- ALTER DATABASE - 修改数据库属性(改)
- SELECT DATABASE()/status - 查看当前使用的数据库
- CREATE TABLE - 创建表(增)
- DROP TABLE - 删除表(删)
- SHOW TABLES FROM - 列出库中的所有表(查)
- SHOW COLUMNS FROM - 列出表中的所有列(查)
- DESCRIBE - 列出表中所有列的类型及属性(查)
- SHOW CREATE TABLE - 列出创建表时的完整结构(查)
- ALTER TABLE - 修改表属性(改)
2、语句用法
2.1、表自身的增删查改
(1)创建数据表:create table tab_name (col_name col_type [属性1],...)[属性2]
-
属性 1:(1)NOT NULL 要求在插入数据时,该列的字段值必须存在不能为空。(2)AUTO_INCREMENT 定义该列拥有自增属性,数值会自动加 1。(3)PRIMARY KEY 定义该列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
-
属性 2:(1)ENGINE 设置存储引擎。(2)CHARSET 设置编码。

(2)删除数据表:drop table tab_name
(3)查看表结构:show columns from tab_name

(4)修改数据表:alter table tab_name operate。其中,operate 的操作有:
- 在表中删除列:
drop col_name - 在表中添加列:
add col_name col_type [first|after col_name]。 - 修改列类型:
modify col_name col_type [属性1]。 - 表名称更改:
rename to tab_name
(5)复制数据表,如下:【注:参考链接】
-- (1)复制表结构到新表
create table tbl_new like tbl_old; #推荐用法
show create table tbl_old; #查看创建某表时的语法
-- (2)复制表结构及数据到新表
create table tbl_new select * from tbl_old; #推荐用法
insert into tbl_new select * from tbl_old; #在只有表结构的新表中插入旧表中的数据)
-- (3)复制表的部分列字段
create table tbl_new as( select id, username as uname, password as pass frome tbl_old) #复制表中的部分列字段并重命名,然后导入数据。
create table tbl_new as( select * from tbl_oldWHERE left(username,1) = 's') #复制表中的全部列字段,然后导入符合条件的数据。
2.2、表数据的增删查改
(1)插入数据:insert into tab_name(col1, col2, col3...)values(val1, val2, val3...)
注:未列出的列使用默认值,若是拥有自增属性的列,则自动加一。values 里的值可以是函数如 val3 可替换为 NOW()。
(2)删除数据:delete from tab_name [where clause]
注:如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除。
(3)查询数据:select col_name1, col_name2 from tab_name [where clause][limit n][offset m]
注:(1)查询语句中你可以使用一个或者多个表,表之间使用逗号分割,并使用 WHERE 语句来设定查询条件。(2)你可以使用星号(*)来代替其他字段,SELECT 语句会返回表的所有字段数据。(3)你可以使用 LIMIT 属性来设定返回的记录数。(4)你可以通过 OFFSET 指定 SELECT 语句开始查询的数据偏移量。默认情况下偏移量为 0。
(4)修改数据:update tab_name set col1=val1_new,col2=val2_new [where clause]
3、从句
3.1、WHERE 从句(优先级 1)
(1)WHERE 表达式子句(精准匹配)
SQL 格式:select col1, col2,... from tab_name1, tab_name2...[where condition1 [and|or] condition2 ...]
注:WHERE 子句也可以运用于 DELETE 或者 UPDATE 命令,它包含的操作符有
>、<、=、!=、>=、<=。
(2)WHERE LIKE 子句(模糊匹配)
SQL 格式:select col1, col2,...from tab_name where col1 like condition1 [AND|OR] col2 = 'somevalue'
注:可以使用 LIKE 子句代替等号,MYSQL 为 LIKE 提供了四种匹配方式,如下:
%:表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
_:表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句。
[]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
[^]:表示不在括号所列之内的单个字符。其取值和[]相同,但它要求所匹配对象为指定字符以外的任一个字符。查询内容包含通配符时, 由于通配符的缘故,导致我们查询特殊字符
% _ [的语句无法正常实现,而把特殊字符用[ ]括起便可正常查询。
(3)WHERE REGEXP 子句(模糊匹配)
SQL 格式:select name from tabl where name regexp ‘^st’
注:与 LIKE 用法相似,只不过它支持正则表达式进行条件匹配。
3.2、GROUP BY 从句(优先级 2)
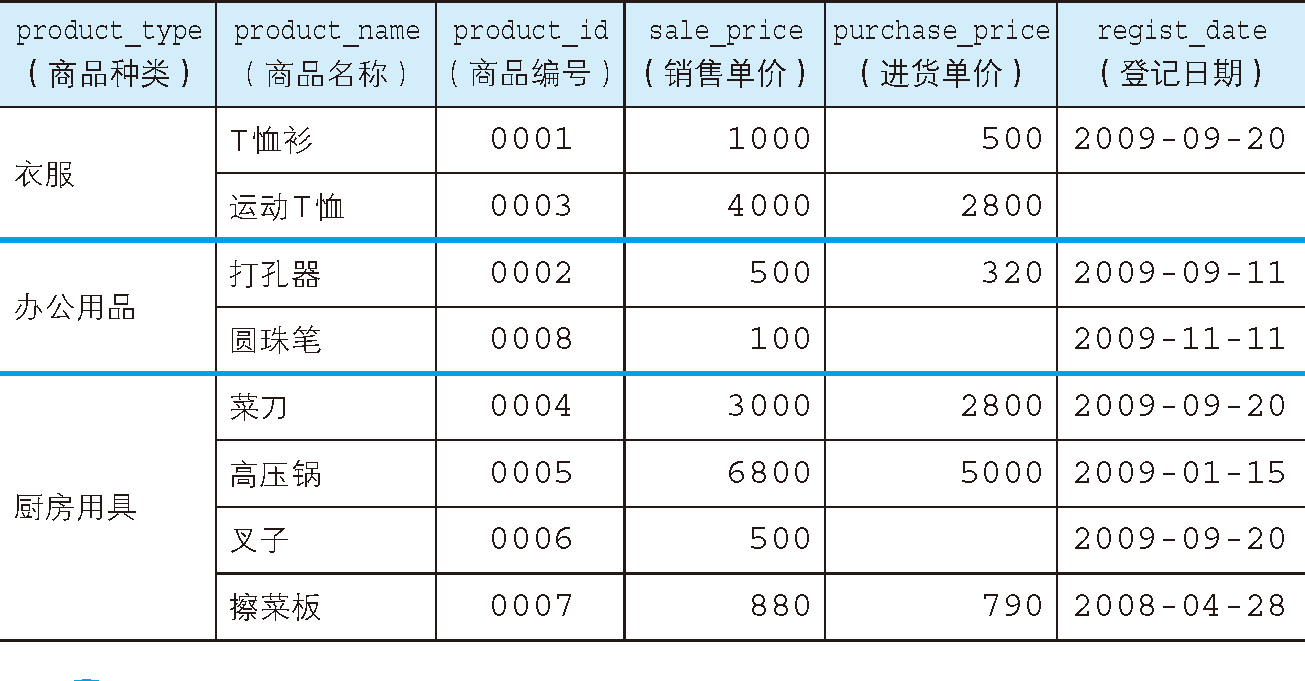
group by 分组语句根据一个或多个列对结果集进行分组(如下图对商品种类进行的分组),在分组的列上可以使用 COUNT, SUM, AVG, 等聚合函数。【注:参考链接】
SQL 格式:select col_name, function(col_name) from tab_name where col_name operator value group by col_name
3.3、HAVING 从句(优先级 3)
HAVING 从句与 WHERE 从句都属于条件过滤,在省略 GROUP BY 从句的情况下,则 HAVING 从句的行为与 WHERE 从句类似。它们之间的主要区别如下:
-
WHERE 从句的作用是在 对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据。where 条件中不能包含聚组函数,使用 where 条件过滤出特定的行。
-
HAVING 从句的作用是筛选满足条件的组,即 在分组之后过滤数据,条件中经常包含聚组函数。 使用 having 条件 过滤出特定的组,也可以使用多个分组标准进行分组。例,
select 类别, SUM(数量) from A where 数量 > 8 group by 类别 having SUM(数量) > 10,having 后面可以使用聚合函数进行条件过滤。
指定任何的字段做为排序的条件,从而返回排序后的查询结果。默认情况下,它是按 asc 升序来排序。
SQL 格式:select col1_name, col2_name...from tab_name order by col1 [asc|desc],col2 [asc|desc] ...
3.4、LIMIT 从句(优先级 4)
限制通过 SELECT 查询返回的结果数量。
SQL 格式 1:SELECT column_list FROM table1 LIMIT row_count
SQL 格式 2:SELECT column_list FROM table1 LIMIT offset,count
4、表连接
4.1、JOIN 连接
表连接的四种方式:
-
INNER JOIN:如果表中有至少一个匹配,则返回行(以左右表为参考,只有左右两表之间的连接条件都满足的列才会被返回,否则不显示数据)
-
LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行(以左表为参考,这说明左表的数据会全部被显示,即使并未满足连接条件,此时右表中不满足的位置会被置为 NULL。)
-
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行(以右表为参考,这说明右表的数据会全部被显示,即使并未满足连接条件,此时左表中不满足的位置会被置为 NULL。)
-
FULL JOIN:只要其中一个表中存在匹配,则返回行(以左右表为参考,即使两表之间的连接条件并不满足,但也会返回数据,只不过左右对应不上的数据以 NULL 填充。)
两表连接用法:SELECT col_name FROM tbZUO INNER JOIN tblYOU ON tblZUO.col_name = tblYOU.col_name
三表连接用法:SELECT article.aid,article.title,user.username,type.typename FROM article INNER JOIN user ON article.uid = user.uid INNER JOIN type ON article.tid = type.tid【注: article-user-type】
注:(1)表连接似乎仅在 SELECT 语句中使用。(2)数据库检索是从参考表某列的每一项开始,依次向被参考表进行条件的比对。若被参考表中无对应值,则默认为 NULL 或不返回。
4.2、UION 连接
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。【注:如果说 JOIN 是将多张 有关联的表 进行了一次列的连接,那么 UION 就是将多张 相同字段列或不相干的列 的行进行了一次拼接。】
SQL 格式:SELECT name1,name2 FROM table1 [WHERE conditions] UNION [ALL | DISTINCT] SELECT name1,name2 FROM tables [WHERE conditions]
注:默认情况下,多个 SELECT 语句会删除重复的数据,即 DISTINCT。
5、数据约束
MYSQL 约束用于 规定表中的数据规则,如果存在违反约束的数据行为,行为会被约束终止。
-
NOT NULL:保证某列不能有空值。
-
UNIQUE:保证某列不能有重复数据。
-
DEFAULT:没有给列赋值时所使用的默认值。【如:
CREATE TABLE Persons(P_Id int NOT NULL, City varchar(255) DEFAULT 'Sandnes')】 -
CHECK:保证列中的值要符合指定的条件。【如:
CREATE TABLE Persons(P_Id int NOT NULL CHECK (P_Id > 0), Address varchar(255) )】 -
PRIMARY KEY:是 NOT NULL 和 UNIQUE 的结合。确保某列(或两个列或多个列的结合)有唯一标识(即唯一性),有助于更容易更快速地找到表中的一个特定的记录。【如:
CREATE TABLE Persons(P_Id int NOT NULL PRIMARY KEY, LastName varchar(255) NOT NULL)】 -
FOREIGN KEY:保证本表中某列数据的值 在另一个表某列的值范围中是存在的。【注:(1)FOREIGN KEY 约束用于预防破坏表之间连接的行为,可以保证两表之间完美衔接。(2)FOREIGN KEY 约束也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。(3)语句用法:
CREATE TABLE Orders(P_Id int FOREIGN KEY REFERENCES Persons(P_Id))】
注:(1)数据库的每张表只能有一个主键,不可能有多个主键。所谓的一张表多个主键,我们称之为联合主键(就是用多个字段一起作为一张表的主键)。(2)父表中的主键是被子表中的外键所参考引用的,先有主键然后才有外键,有主无外可,有外必有主。
6、事务:修改块
在 MySQL 中,事务是一组 SQL 语句的执行,它们被视为一个单独的工作单元,保证成批的 SQL 语句要么全部执行,要么全部不执行。【例如,在人员管理系统中删除一个人员,既需要删除人员的基本资料,也要删除和该人员相关的信息,如此这些数据库操作语句就构成了一个事务。】
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句(即 INSERT/UPDATE 等)后就会马上执行 COMMIT 操作。因此要显式地开启一个事务必须使用命令 BEGIN,或者执行命令 SET AUTOCOMMIT = 0 来禁止事务的自动提交。
-- 开始事务
begin;
-- 执行一些SQL语句
insert into test value(1);
insert into test value(2);
-- 设置回滚点 id1
savepoint id1
insert into test value(3);
-- 设置回滚点 id2
savepoint id2
insert into test value(4);
-- 撤销至回滚点 id1
rollback to id1
-- 撤销以上执行的所有 SQL 语句
rollback; # 回滚
commit; # 提交 执行还留在事务中的修改语句至数据库,并结束本次事务。
-- 注:在本例中相当于什么修改语句都没有被执行。
注:(1)在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。(2)事务主要是用来 管理 insert, update, delete 语句的。(3)事务的用法参考
7、视图:查询块
在 MySQL 中,视图相当于编程语言中的函数,它可以将那些频繁使用且语法复杂的 sql 查询语句提前统一打包,然后在使用的时候,只需一行简单的 SQL 语句便可实现复杂的查询任务。
视图创建:CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition
视图使用:SELECT * FROM view_name LIMIT 0,1000
注:(1)视图仅适用于 SELECT 查询语句。(2)视图还可以被嵌套,一个视图中可以嵌套另一个视图。(3)视图隐藏了底层的表结构,简化了数据访问操作,用户不再需要知道底层表的结构及其之间的关系,也不用再授予用户直接访问底层表的权限,从而加强了数据库的安全性。
8、杂七杂八
(1)MySQL 用户的创建与授权。
-- 创建用户 test 可在任意主机登录。
CREATE USER test@% IDENTIFIED BY 'pass';
-- 授予 test 用户在 database_name 库中拥有 Alter 权限。
GRANT Alter ON database_name.* TO test@%;
-- 授予 test 用户在所有库所有表中拥有不包括 Grant Option 的所有服务器权限。
GRANT ALL/NO ON *.* TO test@%;
-- 授予 test 用户所有服务器权限。
GRANT ALL/NO ON *.* TO user@% WITH Grant Option;